

Categories
Problems that solves
Decentralized IT systems
No IT security guidelines
Unauthorized access to corporate IT systems and data
Values
Ensure Security and Business Continuity
Amazon S3
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance.
About Product
Description
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. This means customers of all sizes and industries can use it to store and protect any amount of data for a range of use cases, such as websites, mobile applications, backup and restore, archive, enterprise applications, IoT devices, and big data analytics. Amazon S3 provides easy-to-use management features so you can organize your data and configure finely-tuned access controls to meet your specific business, organizational, and compliance requirements. Amazon S3 is designed for 99.999999999% (11 9's) of durability, and stores data for millions of applications for companies all around the world.
Main benefits:
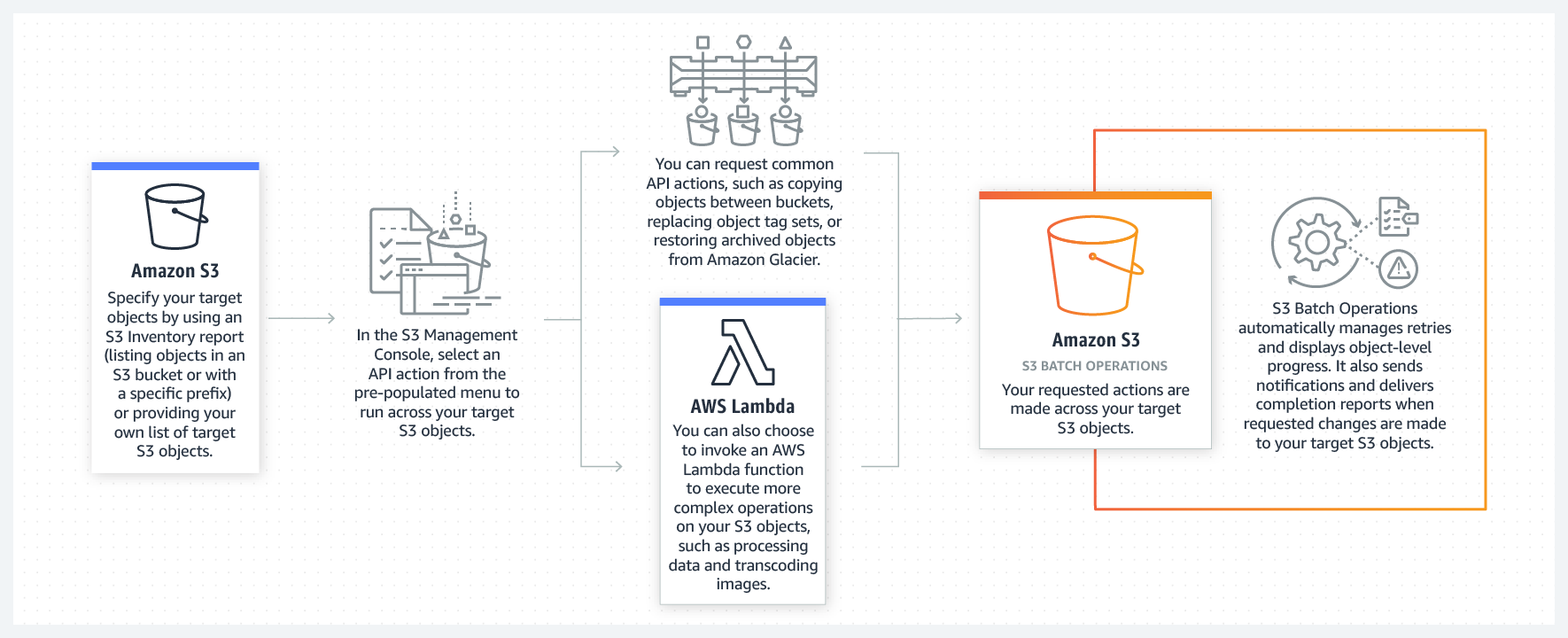
Industry-leading performance, scalability, availability, and durability Scale your storage resources up and down to meet fluctuating demands, without upfront investments or resource procurement cycles. Amazon S3 is designed for 99.999999999% of data durability because it automatically creates and stores copies of all S3 objects across multiple systems. This means your data is available when needed and protected against failures, errors, and threats. Wide range of cost-effective storage classes Save costs without sacrificing performance by storing data across the S3 Storage Classes, which support different data access levels at corresponding rates. You can use S3 Storage Class Analysis to discover data that should move to a lower-cost storage class based on access patterns, and configure an S3 Lifecycle policy to execute the transfer. You can also store data with changing or unknown access patterns in S3 Intelligent-Tiering, which tiers objects based on changing access patterns and automatically delivers cost savings. Unmatched security, compliance, and audit capabilities Store your data in Amazon S3 and secure it from unauthorized access with encryption features and access management tools. You can also use Amazon Macie to identify sensitive data stored in your S3 buckets and detect irregular access requests. Amazon S3 maintains compliance programs, such as PCI-DSS, HIPAA/HITECH, FedRAMP, EU Data Protection Directive, and FISMA, to help you meet regulatory requirements. AWS also supports numerous auditing capabilities to monitor access requests to your S3 resources. Management tools for granular data control Classify, manage, and report on your data using features, such as: S3 Storage Class Analysis to analyze access patterns; S3 Lifecycle policies to transfer objects to lower-cost storage classes; S3 Cross-Region Replication to replicate data into other regions; S3 Object Lock to apply retention dates to objects and protect them from deletion; and S3 Inventory to get visbility into your stored objects, their metadata, and encryption status. You can also use S3 Batch Operations to change object properties and perform storage management tasks for billions of objects. Since Amazon S3 works with AWS Lambda, you can log activities, define alerts, and automate workflows without managing additional infrastructure. Query-in-place services for analytics Run big data analytics across your S3 objects (and other data sets in AWS) with our query-in-place services. Use Amazon Athena to query S3 data with standard SQL expressions and Amazon Redshift Spectrum to analyze data that is stored across your AWS data warehouses and S3 resources. You can also use S3 Select to retrieve subsets of object metadata, instead of the entire object, and improve query performance by up to 400%. Most supported cloud storage service Store and protect your data in Amazon S3 by working with a partner from the AWS Partner Network (APN) — the largest community of technology and consulting cloud services providers. The APN recognizes migration partners that transfer data to Amazon S3 and storage partners that offer S3-integrated solutions for primary storage, backup and restore, archive, and disaster recovery. You can also purchase an AWS-integrated solution directly from the AWS Marketplace, which lists of hundreds storage-specific offerings.
Industry-leading performance, scalability, availability, and durability Scale your storage resources up and down to meet fluctuating demands, without upfront investments or resource procurement cycles. Amazon S3 is designed for 99.999999999% of data durability because it automatically creates and stores copies of all S3 objects across multiple systems. This means your data is available when needed and protected against failures, errors, and threats. Wide range of cost-effective storage classes Save costs without sacrificing performance by storing data across the S3 Storage Classes, which support different data access levels at corresponding rates. You can use S3 Storage Class Analysis to discover data that should move to a lower-cost storage class based on access patterns, and configure an S3 Lifecycle policy to execute the transfer. You can also store data with changing or unknown access patterns in S3 Intelligent-Tiering, which tiers objects based on changing access patterns and automatically delivers cost savings. Unmatched security, compliance, and audit capabilities Store your data in Amazon S3 and secure it from unauthorized access with encryption features and access management tools. You can also use Amazon Macie to identify sensitive data stored in your S3 buckets and detect irregular access requests. Amazon S3 maintains compliance programs, such as PCI-DSS, HIPAA/HITECH, FedRAMP, EU Data Protection Directive, and FISMA, to help you meet regulatory requirements. AWS also supports numerous auditing capabilities to monitor access requests to your S3 resources. Management tools for granular data control Classify, manage, and report on your data using features, such as: S3 Storage Class Analysis to analyze access patterns; S3 Lifecycle policies to transfer objects to lower-cost storage classes; S3 Cross-Region Replication to replicate data into other regions; S3 Object Lock to apply retention dates to objects and protect them from deletion; and S3 Inventory to get visbility into your stored objects, their metadata, and encryption status. You can also use S3 Batch Operations to change object properties and perform storage management tasks for billions of objects. Since Amazon S3 works with AWS Lambda, you can log activities, define alerts, and automate workflows without managing additional infrastructure. Query-in-place services for analytics Run big data analytics across your S3 objects (and other data sets in AWS) with our query-in-place services. Use Amazon Athena to query S3 data with standard SQL expressions and Amazon Redshift Spectrum to analyze data that is stored across your AWS data warehouses and S3 resources. You can also use S3 Select to retrieve subsets of object metadata, instead of the entire object, and improve query performance by up to 400%. Most supported cloud storage service Store and protect your data in Amazon S3 by working with a partner from the AWS Partner Network (APN) — the largest community of technology and consulting cloud services providers. The APN recognizes migration partners that transfer data to Amazon S3 and storage partners that offer S3-integrated solutions for primary storage, backup and restore, archive, and disaster recovery. You can also purchase an AWS-integrated solution directly from the AWS Marketplace, which lists of hundreds storage-specific offerings.
Scheme of work
Competitive products





Deployments with this product











